A Anatomia Matemática do UPC (Universal Product Code)
Para entender a estrutura do UPC, primeiro precisamos quebrar o código de barras em suas menores partes. A menor unidade de um código de barras é chamada de "módulo", com uma largura padrão de 0,33 milímetros (basicamente, é a linha mais fina possível). Ele é incrivelmente pequeno.
Essa padronização de tamanho é mantida pela GS1 (Global System 1), uma organização internacional, neutra e sem fins lucrativos, responsável por desenvolver e manter os padrões globais de comunicação empresarial.
Isso garante que um código de barras impresso no Brasil seja lido exatamente do mesmo jeito na China, nos Estados Unidos ou em qualquer outro lugar.
Você pode ver as regras de tamanho em GS1 - UPC Specifications.
Mas, de forma geral, a GS1 permite que esse tamanho varie um pouco para caber em embalagens diferentes:
- O tamanho mínimo permitido: \(0,26 \text{ mm}\) (usado em produtos bem pequenos, como chicletes ou esmaltes).
- O tamanho máximo permitido: \(0,66 \text{ mm}\) (usado em caixas grandes de papelão em estoques, para o operador conseguir ler de longe).
Quando olhamos para um código de barras de longe, vemos linhas pretas de vários tamanhos (umas finas, outras médias, outras bem grossas). Mas essas linhas grossas são apenas vários módulos pretos colados um ao lado do outro. Na prática, isso significa que estamos codificando uma informação de forma binária:
- Módulo de cor de fundo (Branco): É definido normativamente com o valor lógico \(0\).
- Módulo de cor de primeiro plano (Preto): É definido normativamente com o valor lógico \(1\).
Assim, tudo que temos ali são números codificados em binário. No entanto, não temos apenas o código em si do produto, temos também uma série de módulos que servem para orientar o leitor e garantir que a leitura seja feita corretamente. Dessa forma, podemos dividir um código de barras em três grandes grupos:
-
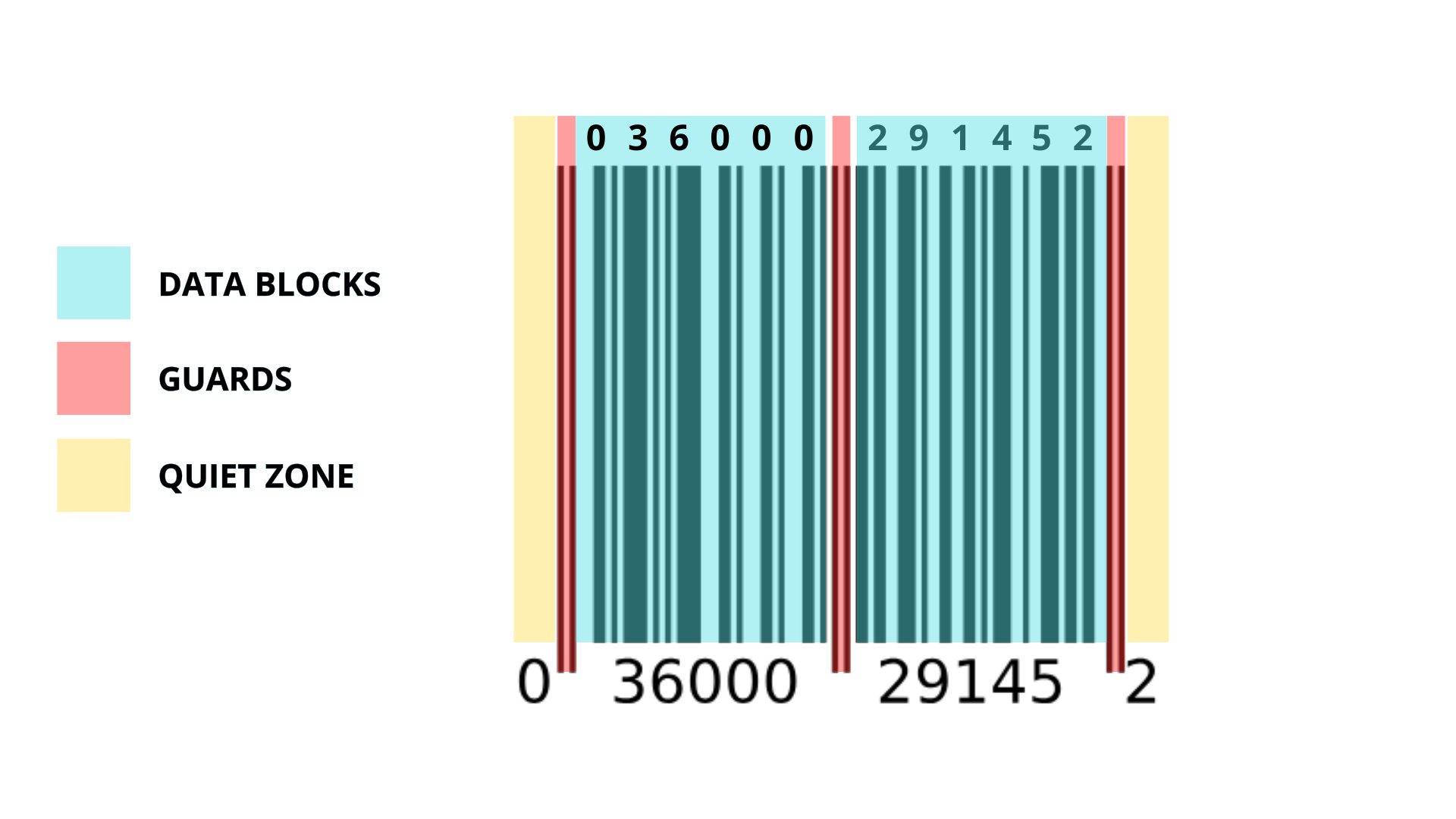
Blocos de dados (Data Blocks): São os módulos que carregam a informação do produto.
No código de barras tradicional (chamado tecnicamente de UPC-A), temos 6 blocos de dados à esquerda e 6 blocos de dados à direita.
-
Portões (Guards): São os módulos que servem para orientar o leitor.
6 módulos formam os portões de segurança (2 na entrada, 2 no meio, 2 na saída).
-
Zona de silêncio (Quiet Zones): É a área em branco antes do código de barras.
É obrigatório ter um espaço em branco de pelo menos 9 módulos de largura antes e depois do código. Isso serve para o leitor entender onde o código começa e onde ele termina.
Por exemplo, um código assim:

pode ser dividido assim:
Como já citado, cada número precisa usar um bloco de exatamente 7 módulos. A imagem abaixo ilustra como cada número é codificado em barras:
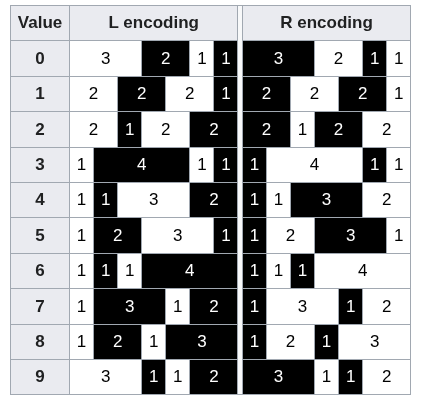
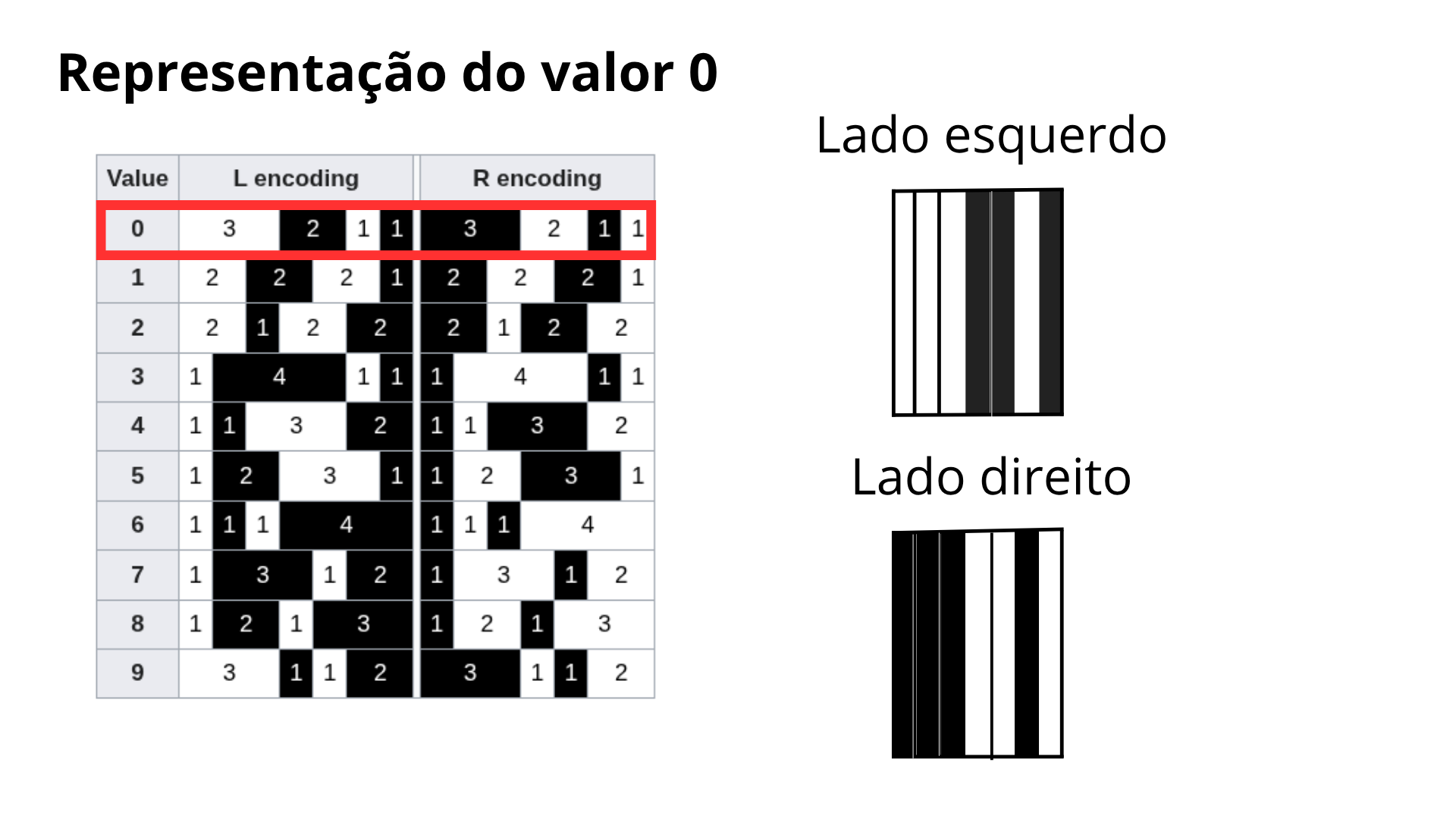
Para ficar mais claro, vamos usar o número 1 como exemplo. A "receita" do número 1 para o lado esquerdo é (3 brancos, 2 pretos, 1 branco, 1 preto):
Já para o lado direito do código, a receita do número 1 é diferente (basicamente é o inverso, onde era preto fica branco e vice-versa):
Podemos ver essa disposição melhor na imagem abaixo:
Por que existe essa diferença?
A mudança de receita existe por um motivo simples: dar o sentido da direção para o computador, da mesma forma que uma placa de trânsito diz se uma rua é "mão" ou "contramão".
Por exemplo, se o número 1 fosse desenhado igual na esquerda e na direita, a estrada de fatias seria idêntica. Quando o produto passasse de cabeça para baixo, o laser começaria a ler o código pelo fim (pela direita) achando que era o começo (a esquerda).
O computador leria todos os números de trás para frente. Em vez de ler o código real do produto, ele leria uma sequência totalmente errada, o sistema não encontraria o preço e o caixa travaria.
É por isso que há esse truque de espelhar a receita de cada número. Assim:
- No Lado Esquerdo: Todos os números (de 0 a 9) foram desenhados com um número ÍMPAR de fatias pretas.
- No Lado Direito: Todos os números foram desenhados com um número PAR de fatias pretas.
Assim, quando o laser cruza o código de barras, a primeira coisa que o software faz é contar a paridade dos blocos de 7 fatias que ele acabou de ler. Se o resultado for ímpar, ele sabe que está lendo o lado esquerdo. Se for par, ele sabe que está lendo o lado direito.
Dessa forma, caso esteja sendo lido invertido, em vez de dar um erro e travar o caixa, o computador simplesmente faz uma operação matemática interna: ele espelha e inverte a ordem dos bits na memória, transformando o que ele leu de trás para frente no código correto.
Levando em conta essa organização, todo código UPC-A tem exatamente 30 barras pretas. Como ele usa 12 dígitos para dados, isso significa que a capacidade máxima é de 100 bilhões de combinações de produtos diferentes (\(10^{11}\) ou \(100.000.000.000\)). É espaço de sobra para registrar produtos por décadas.
E o que são aqueles números embaixo?
Quando olhamos para um código de barras impresso na embalagem de um produto, costumamos ver alguns números alinhados embaixo das barras. Como já citado, eles são exatamente os números que estão codificados nas barras. Foram feitos para que os humanos possam ler o código de barras caso seja necessário digitá-lo manualmente em algum sistema devido a algum problema.
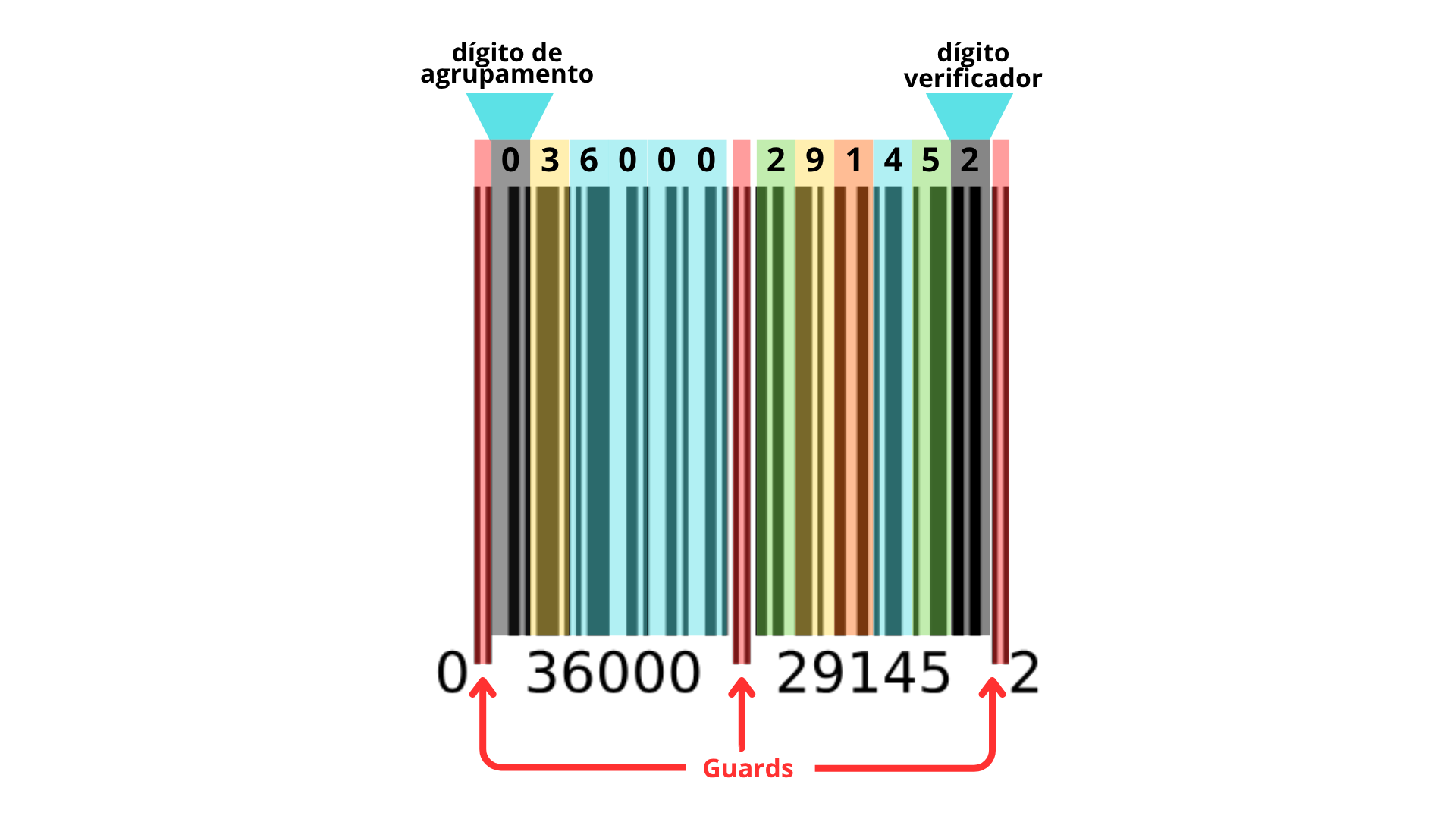
Porém, se você reparar bem na organização de um código do tipo UPC-A, vai notar que o primeiro número e o último ficam "jogados" para fora, meio isolados nos cantos. No nosso exemplo anterior, temos o 0 e 2 isolados nas extremidades:
Segundo as regras oficiais da GS1, eles significam:
- Esquerdo: É o dígito de agrupamento. Ele identifica o tipo de produto ou categoria ao qual o item pertence (no exemplo, é o número 0).
- Direito: É o dígito verificador. Ele é usado para garantir que o código de barras foi lido corretamente (no exemplo, é o número 2).
Dígito de Agrupamento
Esse primeiro dígito (que fica isolado no canto esquerdo) avisa ao computador da loja com que tipo de produto ele está lidando:
| Código | Descrição |
|---|---|
| 0, 1, 6, 7, 8, 9 | Reservado para produtos comuns de supermercado, nos quais os números seguintes identificam a fábrica e o produto. |
| 2 | Reservado para itens pesados na hora (como carne, queijo ou frutas). Quando o mercado embala uma bandeja de carne, o próprio mercado gera esse código. O sistema lê o número 2, entende que é um item de peso variável e usa os últimos números do código para puxar o peso ou o preço direto da balança. |
| 3 | Reservado para medicamentos e remédios (nos EUA, os números do meio correspondem ao registro oficial de drogas do governo, o NDC). |
| 4 | Reservado para uso interno da própria loja, geralmente usado em cartões de fidelidade ou cupons de desconto do próprio estabelecimento. |
| 5 | Reservado para cupons de desconto de fabricantes (aqueles que dão desconto cumulativo em produtos específicos). |
Dígito Verificador
A única função dele é responder a uma pergunta para o computador: "As barras foram lidas corretamente ou o código está riscado, sujo ou amassado?"
Quando o laser passa pelo código de barras, o computador lê os 11 primeiros números e, em uma fração de milissegundo, faz uma conta matemática com eles. O resultado final dessa conta obrigatoriamente precisa dar igual ao último número.
Veja os detalhes matemáticos e o passo a passo de como fazer essa conta em: Como funciona o dígito verificador do código de barras
E o resto? (Código da Empresa e do Produto)
Os valores numéricos centrais são os dados em si, ou seja, o código do produto. Geralmente, são divididos entre código da empresa e código do produto. Então, usando aquele código de barras de exemplo:
- 36000: Código da empresa (identifica quem fabricou ou distribui o produto). Por exemplo, sinaliza que o produto foi fabricado por "Colgate-Palmolive".
- 29145: Código do produto (identifica o produto específico). Por exemplo, pode ser o "Creme Dental Colgate Total 12 de 90g".
As empresas não inventam os códigos do nada; elas alugam um bloco exclusivo de números da GS1 para garantir que nenhuma empresa no mundo tenha um código igual ao seu. A divisão do código depende do tamanho da fabricante. Grandes corporações recebem um prefixo de empresa curto (deixando mais dígitos livres para cadastrar milhares de produtos). Pequenos produtores recebem um prefixo longo (deixando poucos dígitos, o suficiente para uma linha pequena de produtos).
Algo muito parecido com a divisão de IPs, onde uma faixa maior ou menor é separada para os hosts ou roteadores, dependendo do tamanho da empresa.
Para ver melhor, veja o mesmo código com detalhes para entender cada parte: